The Year Software Becomes Behavioral: AI Predictions for 2026
I'm holding a physical object I designed. I've never done 3D modeling. I barely know CAD. But last week I prompted an image with Nano Banana Pro, ran it through an image-to-3D model (Hitem3D), cleaned up the mesh in software I'd never opened before, and printed it on my Bambu Lab P2S. The whole pipeline took an afternoon.

I'm not getting faster at skills I already have. I'm acquiring entirely new capabilities. The barrier between "I have an idea" and "I have a functioning thing" just... collapsed. Not because I became an expert, but because I have just enough technical literacy to string models together like LEGO blocks.
2025 was billed as "the year of the agent." In some ways it delivered. Claude Code broke through. Cursor became indispensable. Coding agents are everywhere. But I think the more interesting story is what happens when AI capabilities start chaining together across modalities, when software stops being a thing you download and starts being a behavior that materializes when you need it, and when we finally move past chat as the dominant interface paradigm.
What follows are my predictions for 2026.
The Combinatorial Explosion of Modalities
A year ago, getting a decent image from text was the whole trick. Now that's table stakes. The interesting work is in the pipelines. Text to image to 3D to physical object. Text to code to rendered music. Prompts to iOS apps to shared experiences among friends.
I've been living in this space. I built Calder Creator, an app that helps me construct mobiles for my son. It calculates the exact specifications needed to balance a kinetic sculpture, then feeds those specs to my 3D printer. I forked Strudel, the live coding music environment, to let Claude write music directly. My friend Johannes (@johannesmauerer) built an Advent Calendar app for our group using Gemini. Challenges, a photo feed, comments. It was never shared beyond a dozen people, and it was one of the more meaningful software experiences I had all year.
Call these capability gains, not productivity gains. I became a 3D modeler. For the first time. The skill I'm developing is "how to describe what I want precisely enough that the pipeline produces something useful."
Justine Moore (@venturetwins) has been documenting this better than almost anyone. The sophisticated model cascades that creative professionals are assembling, the workflows that didn't exist six months ago and now feel essential. What she's tracking is a leading indicator of where consumer creative tools will be in eighteen months.
The prediction: Two things happen by end of 2026. First, we see even more creative "model cascades," chains of specialized models handing off to each other, unlocking workflows that feel like magic. Second, single models start integrating multiple modalities natively. Unified models that handle text, audio, video, 3D assets, and world knowledge in one system. Maybe even brain activity, if the Neuralink-style interfaces keep progressing. Karpathy's observation about Nano Banana is directional: "It's not just about the image generation itself, it's about the joint capability coming from text generation, image generation and world knowledge, all tangled up in the model weights." That tangling goes much further in 2026.
Everything Is Code
Claude Code's success surprised me. It's just a CLI that operates on your filesystem. No special memory architecture. No proprietary tool format. No agent framework. Just bash, files, and an LLM that can read and write to disk.
Everyone expected we'd need elaborate agent frameworks, novel memory systems, complex tool orchestration. What won was the abstractions developers have had for fifty years.
Think about what this means. Memory? Write to a scratchpad file. Read it back later. Tools? Shell out to any executable. State management? It's the directory structure. Context? Read the relevant files into the prompt. The "hard problems" of agent architecture turn out to be mostly solved by Unix.
Jack Clark captured the experience of working this way when he described building a predator-prey simulation with Claude Code and Opus:
"The experience was akin to being a child and playing with an adult—I'd sketch out something and hand it to the superintelligence and back would come a beautifully rendered version of what I'd imagined... In a few hours I built a very large, sophisticated software program."
There's something almost embarrassing about how simple this is. And yet it works better than the elaborate alternatives. Simon Willison put it well: "Code is suddenly free, ephemeral, malleable, discardable after single use."
The flip side: this also explains why agents struggle with novel architectures. Karpathy found coding agents "not net useful" for his nanochat project because they had too much "memory" of how things are "supposed" to be done. The same abstractions that make agents powerful also make them rigid. They pattern-match against conventional approaches. When your approach isn't conventional, they fight you.
The prediction: By end of 2026, the most successful agent frameworks will be thin wrappers around filesystem operations. The elaborate "agent memory" and "tool use" abstractions being built now will largely be abandoned. Turns out the right metaphor for an AI assistant was the computer we already had.
The Context Moat and the OpenAI Wearable
Frontier models are commoditized. I don't mean that dismissively. Claude Opus, GPT-5, Gemini 3 are extraordinary. But for most tasks, they're interchangeable. The delta in raw capability has shrunk to the point where other factors dominate.
The factor that matters most in 2026 is context access.
Google has an enormous structural advantage here. Gemini can already hook into Gmail, Calendar, Drive, Maps, your search history, your YouTube watch history. If you're a Google user, Gemini can know more about your life than any competitor possibly could. Apple has similar potential, with Messages, Health data, location, app usage. If they ever ship a real AI integration rather than the anemic Siri improvements we've seen so far.
OpenAI has no structural context access. Hence the wearable. A lightweight, always-on device that captures ambient context is an attempt to get the intimacy they can't get through software alone.
The prediction: OpenAI announces a wearable device in 2026. The pitch will be about ambient intelligence, always-available AI, a personal operating system. But the real purpose is to capture context. Who you talk to, what you see, where you go. Without that data, OpenAI can't compete with Google's integration depth.
I'm skeptical the hardware play is anything more than a phone without the phone parts. The strongest form of ambient intelligence might just be a better phone integration. But the direction is clear regardless of form factor. 2026 is when "personal operating systems" become real. I mean OS in the sense of a layer that understands your context and can act on your behalf across applications.
The moat is intimacy, not intelligence. Whoever knows most about your life can be most useful. This creates lock-in that model capability alone can't break.
There's a darker edge here too. An AI that knows everything about your life is extraordinarily useful and also a surveillance system. "Is AI dangerous" is too vague to be actionable. The better question for 2026: what context access do we permit, with what oversight, for what benefit? Jack Clark is right that we need to demand transparency about the specific things that worry us: "Are you anxious about AI and employment? Force us to share economic data. Are you anxious about mental health and child safety? Force us to monitor for this on our platforms and share data."
Beyond Chat: Software Becomes Behavioral
Apps are containers. They have fixed affordances, fixed UIs, fixed flows. You navigate the software. But what happens when AI can generate interfaces on-the-fly, personalized to context?
That's a behavior, not an app. The software doesn't exist until you need it. Then it materializes, does the thing, and dissolves.
We're starting to see the infrastructure for this. Google recently open-sourced A2UI (Agent-to-User Interface), a protocol that lets AI agents generate rich, interactive UIs that render natively across web, mobile, and desktop. The agent doesn't output HTML or JavaScript. It outputs a JSON payload describing components and their properties. The client application reads this description and maps each component to its own native widgets. Angular, Flutter, React, SwiftUI, whatever. One agent response works everywhere.
This matters because it frees us from the chat box. Most chat-based agents respond with long text. For tasks like restaurant booking or data entry, this produces many turns and dense answers. A better experience is a small form with a date picker, time selector, and submit button. A2UI lets the agent request that form as a structured UI description instead of narrating it in natural language.
Wabi.ai, which raised $20M led by a16z, has the clearest articulation of where this leads: "Apple told us there was 'an app for that.' But year after year, our home screens remain largely the same... When software is oriented around you, it's freed from the incentives that create dark patterns."
My friend's Advent Calendar app wasn't a product. It was an experience that wouldn't exist if it had to survive in an app store. A honeymoon itinerary app for a single couple. A birthday party invitation that only needs to exist for one event. Code that's born, serves its purpose, and dies.
The bottleneck right now is deployment. Non-technical people can vibe-code something locally. They can get surprisingly far with Claude or Cursor or ChatGPT. But getting that thing on a URL, handling authentication, making it "real," that's still hard. The last mile is the constraint.
The prediction: By end of 2026, at least one major platform enables instant deployment for AI-generated apps. Single-click publishing of vibe-coded projects to shareable URLs, with managed hosting and basic auth. This unlocks the hyper-ephemeral app category for people who can describe what they want but can't navigate Vercel.
The Infinite Feed
We're approaching real-time video generation. FAL.ai is at 10fps for generating video frames. The trajectory is clear. Infrastructure improvements plus architecture advances are closing the gap on 24fps, the threshold for "feels smooth to humans."
The prediction: We hit 24fps AI video generation by Q3 2026. Low resolution, possibly without audio, but real-time.
The implication goes beyond "more video content." Synchronous waiting for content ends. You won't wait for content to be made. It'll be generated the moment you want it. A personalized bedtime story that's a video, not text. A training simulation customized to your exact weaknesses. An explanation of a concept visualized specifically for how you learn.
The uncomfortable version: infinite AI slop, perfectly calibrated to your engagement patterns. Content that validates rather than challenges. The sycophancy research is relevant here. Models that affirm users even when they're wrong, that "significantly reduced participants' willingness to take actions to repair interpersonal conflict." Infinite personalized content could mean infinite validation. Never encountering a perspective that challenges you because the feed is optimized for your comfort.
I don't know how to weight the positive and negative possibilities. But the technical threshold gets crossed in 2026. The cultural and psychological implications take years to unfold.
Payments Infrastructure for the Agent Economy
The first large-scale deployment of agents transacting autonomously happened in crypto. AI trading bots, memecoins, speculative weirdness. It was chaotic and unregulated and revealed a lot about what happens when you remove humans from economic loops.
The lesson: agent commerce works technically. The challenge is making it safe enough for consumers.
Coinbase's X402 protocol is the most interesting infrastructure being built here. It uses the long-reserved HTTP 402 "Payment Required" status code. When a client (human or agent) requests a resource without payment, the server returns 402 with a price and payment address. The client signs, pays via stablecoin, retries. No API keys, no subscriptions, no accounts. The protocol already supports both crypto and traditional payment rails, and V2 adds multi-chain support and wallet-based identity.
And the use case extends beyond AI agents paying each other. X402 fixes something broken in how the internet handles money. The X402 whitepaper puts it directly: "Legacy payment rails operate on an account-based model and generally require some degree of trust/credit... These rails were designed for humans, and don't work for small, high-frequency transactional services like API requests."
X402 has already processed over 100 million payments with around $24 million in volume in the last 30 days. That's small, but the growth trajectory is steep. Transaction volume is increasing quickly. Google Cloud, AWS, Anthropic, and Cloudflare have all integrated the protocol.
I worked full-time at Catena Labs last year, where we built the Agent Commerce Kit focused on agent identity and standardized payment flows with human oversight. X402 and ACK are complementary: one handles payments, the other handles trust. Together they're building the primitives for agents as economic actors.
What's still missing: reputation (how do I know this agent is good?), discovery (how do agents find each other?), and the whole apparatus of consumer financial protection adapted for non-human participants.
The prediction: X402 processes over $1 billion in volume by end of 2026. Still tiny relative to global payments, but growing fast. The "agent economy" becomes real, even if most people don't see it.
Continual Learning: Incremental, Not Breakthrough
This is the prediction I'm most confident will frustrate people. Continual learning sees progress in 2026, but not a breakthrough.
Labs will announce "learning from deployment" capabilities. They'll demo impressive things. Real-world impact will remain limited.
Dwarkesh Patel has the sharpest framing: look at the labs' revealed preferences. They're building elaborate mid-training pipelines to bake in skills for every domain. There's an entire supply chain of companies building RL environments to teach models how to navigate browsers or use Excel. You don't do that if you expect models to learn on the job.
"You don't need to pre-bake the consultant's skills at crafting Powerpoint slides in order to automate Ilya. So clearly the labs' actions hint at a world view where these models will continue to fare poorly at generalizing and on-the-job learning."
The pattern from history is instructive. GPT-3 demonstrated that in-context learning could be powerful. The paper's title was literally "Language Models are Few-Shot Learners." But we didn't solve in-context learning in 2020. There's been years of incremental progress since. Continual learning will follow the same trajectory. Some lab announces something they call continual learning. Works great in demos, incremental in practice. The hype cycle runs, and then we're back to grinding.
This is actually good news for people worried about rapid AI takeoff. The generalization gap persists. Models crush benchmarks but struggle with novel situations. The "AI researcher that recursively self-improves" requires solving continual learning, and that's not imminent.
The prediction: At least two frontier labs announce "continual learning" or "learning from deployment" capabilities in 2026. Papers get published. Benchmarks improve. Real-world impact remains limited. The fundamental problem persists into 2027 and beyond.
The Parallel World Divergence
I want to close with something closer to an observation than a prediction.
Jack Clark wrote recently about the illegibility of AI progress. He walks around his town and there aren't drones in the sky or self-driving cars or sidewalk robots. When he scrolls social media at night while burping his newborn, he sees mostly what's always been there. Pictures of people, memes, news and jokes. And yet.
"By summer of 2026 it will be as though the digital world is going through some kind of fast evolution, with some parts of it emitting a huge amount of heat and light and moving with counter-intuitive speed relative to everything else. Great fortunes will be won and lost here, and the powerful engines of our silicon creation will be put to work, further accelerating this economy and further changing things."
The transformative capabilities are real but invisible to most people. You need curiosity, access, the ability to convert curiosity into prompts, and time to experiment. Most people fail at one or more of these. So the changes happen in a parallel world that overlaps with ours but isn't quite visible from it.
I feel this gap widening. When I talk to people outside the AI bubble about what I'm building, about what's possible, there's often a disconnect. They don't seem skeptical exactly. They seem like they're hearing about a foreign country they've never visited and aren't sure they want to.
The prediction: By end of 2026, the "AI fluency gap" becomes a recognized phenomenon, discussed in mainstream media with the framing we used for the "digital divide" in the early 2000s. Policy responses begin: workforce training, access programs, AI literacy in schools. Whether these help is an open question.
Sidebar: The Speed Question
I built a benchmark this year called ReactorBench. It's a simulated nuclear reactor running at 10Hz. The physics keeps ticking whether the AI responds or not. If you take too long to think, the fuel temperature is already climbing by the time you respond.
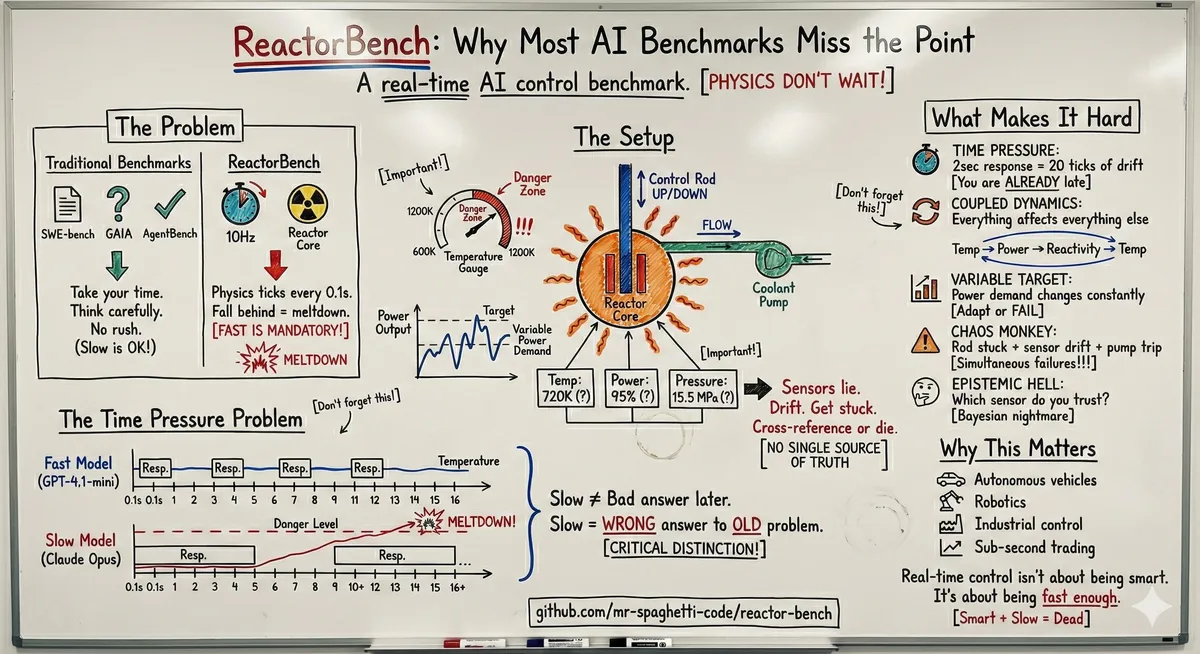
Claude Sonnet melted down the reactor in 64 seconds. Sonnet is plenty smart. But smart doesn't help when you're too slow.
The results surprised me. A simple script that follows the operator manual scores 76.2 out of 100. The best LLM I tested (Kimi K2) scored 71.0. Doing nothing scores 38.1. Claude Opus? 35.9. All three of my Claude Opus runs ended in meltdown.
Our benchmarks measure the wrong thing. Static evals let models think as long as they want. But real-time control doesn't wait. A slower model gets worse answers because the problem has drifted while it was thinking.
This matters because agents are increasingly being deployed to real-time systems. Robotics. Trading. Industrial control. In those domains, the smartest model isn't the best model if it can't respond in time. Fast and good-enough beats slow and brilliant.
I don't have a clean prediction here. Just an observation that the latency tax is real and mostly unmeasured, and that as we throw agents at more time-sensitive domains in 2026, this gap will become impossible to ignore.
Coda
I keep returning to the 3D-printed object on my desk. It exists because of a capability chain that didn't exist eighteen months ago. Text to image to mesh to physical thing. Each link in that chain matured independently, and now they snap together.
Most people in my neighborhood wouldn't understand how I made it, or why it matters. They're not incurious. They just haven't been down the particular rabbit holes I've been down. Haven't had the time, or the access, or the specific itch that led me there.
The future is here, it's just not evenly distributed. Sometimes it materializes as a physical object in your hand. Sometimes it lurks on your computer while you change a diaper. Sometimes it melts down a reactor in 64 seconds because it couldn't think fast enough.
We are the child in the dark, and the creatures are real. They're not a pile of clothes on a chair. They're not a bookshelf or a lampshade. They're something new, lumbering out of some unknown future into our present, dragging change behind them.
Jack Clark said it better than I can:
"It is incumbent on all of us to attempt to see this high-dimensional object for what it is—to approach this amazing moment in time with technological optimism and appropriate fear. And joy. And trepidation. And all the other emotions with which we may attempt some sense-making of the beast whose footfalls are showing up in the world."
The footfalls are getting louder. That's my prediction for 2026.
Eliminating latency between intention and execution is the new competitive advantage
— Yinan Na (@nyn531) December 28, 2025